コラム:TextMeshProで日本語や多言語対応したフォントアセットを作る

投稿日:2024年1月10日 | 最終更新日:2024年3月31日
目次
概要
TextMeshProは、日本語などの文字数の多いフォントアセットを作ろうとした場合にどうすればいいのかが非常に分かりづらくなってしまっています。
これは、TextMeshProが英語圏で開発されたという経緯があると思われます。
まだ改善の余地はあると思うのですが、しばらくは他機能との統合を優先し、基本的な機能のアップデートはしないということです。
現状だとなかなか画一的な答えはなく、使いたい文字の数や多言語対応の有無、フォントに回せるリソース(消費するファイルサイズやメモリサイズ)など、色々な条件よって最適な方法が異なっていたりします。
とはいえ、作成にかなり処理時間がかかるので試行錯誤もしづらいというのが難点です。
ここではどの項目をどう設定すればいいかについて、ベストとは言わずともベターな方法をまとめておきました。
FontAsset Creatorの設定の仕方
フォントアセットを作成するにはFontAsset Creatorを使います。
基本的な使い方は、FontAsset Creatorのドキュメントを参考にしてください。
今回のケースでは、基本的な設定項目はこのようになります。
青で囲った部分の項目は、必要に応じて調整する必要があります。
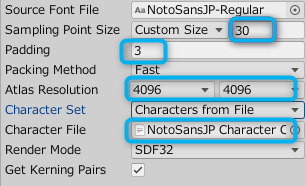
Source Font File
元となるフォントファイルを設定してください。
Samping PointSizeとPadding
「CustomSize」にして「Samping PointSize」を固定にすることを推奨します。
Samping PointSizeは高いほうが高精細に描画できますが、大きいほど必要となるテクスチャサイズも肥大化してしまうので、適度な値に抑えるのがベターです。
(フォントファイルにもよりますが)30以上の値であれば違和感なく表示できると思います。
(実際にフォントを作成したのち、「鬱」などのように細かい文字を表示してみて問題ないかチェックしてください)
「Padding」の値は、「Samping PointSize」の10%以上が推奨になります。
「SP/PD Ratio」はマテリアルエフェクトの表示範囲の限界値でもあるため、高いほうがマテリアルでつけるエフェクトの自由度が上がります。
消費リソースが多くなってもエフェクトに凝るようなリッチな作り方をする場合は20%にしておいたほうが無難です。
| Samping PointSize | Padding | 用途 |
|---|---|---|
| 30 | 3 | 「SP/PD Ratio」が10% 通常のテキストを想定する場合 |
| 30 | 6 | 「SP/PD Ratio」が20% マテリアルのエフェクトに凝ったテキストも想定する場合 |
TextMeshProでは「Samping PointSize」と「Padding」の比率が非常に重要なパラメータとなっています。詳細:Paddingの与える影響
この比率が変わってしまうとエフェクトの大きさが変わったりフォールバックで不具合を起こしたりしてしまうので、比率が変わりがちなAutoSizeはあまり推奨できません。
「AutoSize」設定はどちらかというと「設定した条件下でのなるべく大きなSamping PointSizeとPaddingの値を調べる」ためのものと考えたほう良いです。
TextMeshPro3.2以降ではPaddingに比率(パーセント)を指定することもできるようになったのですが、
20%と指定しても18.5%くらいの結果になったりと、誤差をかなり許容するようなので「比率を固定する」という目的に使うには微妙そうです。
Packing Method
推奨設定は「Fast」です。
テクスチャ描きこむ前段階の、テクスチャにグリフ(文字画像)を並べる方法の設定です。
「Fast」で作る方が早いです。数十秒ほどです。
一応「Optimum」を使うと同じサイズのテクスチャにより多くの文字を収録できるのですが、文字数が多い場合は数十分近い処理時間がかかります。
一応、英語の公式ドキュメントでは「Fast」はサイズを決めるためのテスト用、「Optimum」は本番用となっているのですが、
収録できる文字数が多少増えたところで、必要となるテクスチャサイズは変わらないことが多いので「Fast」でも問題ないことが多いかと思います。
ギリギリまで詰めて作成すればテクスチャサイズが減らせるといった場合に「Optimum」を検討しましょう。
PointSizeの設定を「AutoSize」にしていた場合は(サイズが増やせる可能性があるので)多少描画クオリティが上がることがあるとは思うのですが、
上記の理由でAutoSizeは推奨できませんので、理論上はPacking Methodの違いによって描画クオリティは変わらないと思います。
Atlas Resolution
推奨設定は4096×4096です。
作成するテクスチャのサイズです。文字数が多い場合は、なるべく大きなサイズが必要になります。
最大設定値は8192ですが、対象プラットフォームを考慮する必要があります。
たとえば、Androidの一部の端末は4096までしかサポートしていないため、その対応を想定するなら4096以下にする必要があります。
基本的には4096×4096にして、文字数が少ない場合はそれに合わせて減らしてください。
Character Set
収録する文字の設定です。
「Charaters from File」にして、収録する文字のリストのテキストファイルを「Character File」に設定します。
テキストファイルはコラム:文字セットを参考に決めましょう。
日本語であれば、Adobe-Japan1-4.txtか、Adobe-Japan1-7.txtを使うのが無難です。
Rende Mode
推奨設定はSDF32です。
使用する描画モードです。
日本語などの細かい文字の場合は「SDF32」がベターです。
Get Kerning Pairs
推奨設定はONです。
カーニングペアなどで利用するGlyph Adjustment Tableを読みこむかの設定です。作成されるテクスチャの内容や描画精度には関わりません。
基本的にはONで良いのですが、現在のところ対応するフォントが少ないためONにしても機能することはあまりないようです。
フォントアセットを作成する
設定値が決まったら、FontAssetCreatorで作成をします。詳細はFont Assetの作成を参照してください。
文字数が一つのフォントアセットに入りきらない(Excluded charactersが0にならない)場合は、下記のフォールバックを使って、複数に分割したフォントアセットを作るを
ローカライズを想定する場合は、下記の複数言語対応を参照してください。
フォールバックを使って、複数に分割したフォントアセットを作る
フォールバックを使うと、フォントアセットに複数に分割することができます。
この仕組みを使って、1万字を超えるような大量の文字に対応できるフォントアセットを作ることができます。
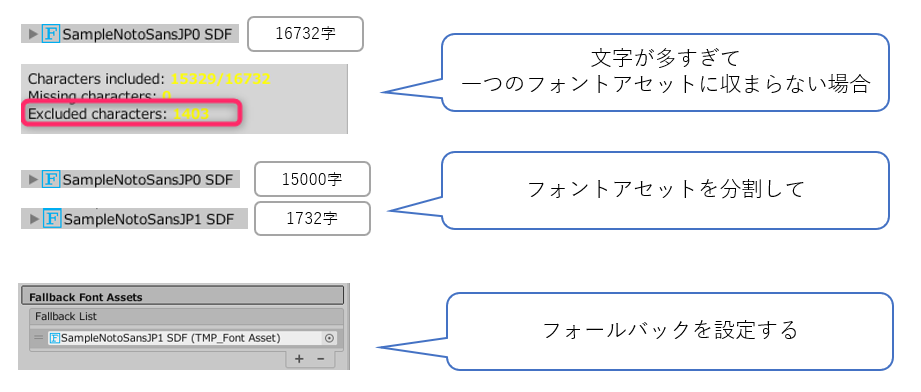
フォールバック用のフォントアセットの項目の設定
FontAsset Creatorの基本的な設定項目は、「Atlas Resolution」と「Character File」以外は変わりません。
特に、「Samping PointSize」と「Padding」はすべて統一するようにしましょう。
繰り返しになりますが、「Samping PointSize」と「Padding」の比率が変わってしまうと不具合を生じやすくなるのでここを統一することが非常に重要になります。
詳細:Paddingの与える影響
「Atlas Resolution」は、追加の最後のぶんは可能なかぎり小さいテクスチャサイズになるように調整しましょう。
文字セットを分割
文字セットは適度な形で分割する必要があります。
ログの数値で分割
基本的にはFont Assetを作成したときのログから、収録できた文字数や入りきらなかった文字数がわかるので、それをもとに文字セットのテキスト内容を手動で分割して、複数のテキストファイルにします。
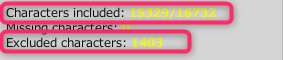
「PackingMethod」を「Optimun」にして、最適なグリフの並べ方をしたときのログを元にして区切っていくのがベストですが、ログが出力されるまではかなり時間がかかります。
また、ログ通りにあまりギリギリな文字数を設定しても、1文字ごとに増減するグリフの面積は一定ではないため、ある程度の余裕を持たせる方がよいと思われます。
テクスチャサイズは倍々で変化するため、シビアに区切っても最終的な合計テクスチャサイズはあまり変わらないことが多いので、
「Fast」設定である程度の余裕を持った文字数で区切って分割していくのが現実的かもしれません。
文字セットの規格の段階でわける
応用として、Adobeの文字コレクションのような文字セットの規格の区切りで分割設定するという方法もあります。
「一つの目のフォントアセットにはAdobe-Japan1の0から4までを使用、2つの目のフォントアセットにはAdobe-Japan1の5から7までを使用」のように分けるイメージです。
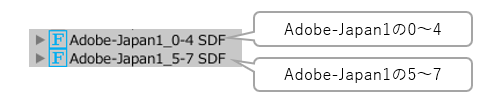
基本的にはAdobeの文字コレクションは数値が高いほど滅多に使われない文字セットになっていくので、フォールバックが使用されづらくサブメッシュの生成を抑えられるというメリットがありますが、
1つのフォントアセットにおさめる文字数の配分の効率が悪いので、場合によっては「Adobe-Japan1の0から4と、5の一部」「Adobe-Japan1の5の残りと6から7まで」のように工夫したほうが良いでしょう。
一つのフォントアセットに収録できるグリフ数を見積もるには
フォントアセットに収録できる文字数をある程度事前に見積もれるようになると、手間を省くことができます。
1グリフの一辺の長さは「Samplieng PointSize + Padding×2」と見積もれます。
逆算すると、「Atlas Resolutionのサイズ」/(Samplieng PointSize + Padding×2)が、Atlas Resolution一辺に収録できるグリフ数なので、その二乗が収録できる総グリフ数の見積もりとなります。
| Size | Padding | Atlas Resolution | 一辺のグリフ数 | 総グリフ数 |
|---|---|---|---|---|
| 30 | 3 | 4098x4098 | 113 | 12769 |
| 30 | 6 | 4098x4098 | 97 | 9409 |
8196x8196であれば4倍、8196x4098で2倍、4098x2028で1/2、2028x2028で1/4がおおよその見積もりになります。
実際には、aやbのような小文字であればもっと小さいサイズしか使わないですし、iや1などのように細い文字であれば横幅は少なくすむなど収録する文字によって違いがでてきます。
アルファベットなどの半角文字は小さく、漢字などの全角文字は大きいので、基本的にはアルファベット圏のフォントは見積もりよりたくさんの文字を収録でき、漢字圏のフォントは若干少なくなる傾向があります。
また、1文字=1グリフではないため、実際に収録できる文字数はグリフ数よりも多くなります。
フォントファイルごとにも違いがあるので、あくまでおおよその見積もりになります。
おおざっぱに「4098x4098のフォントアセット1つにつき約1万文字」と覚えておくとイメージがつきやすくなると思います。
多言語対応(ローカライズ)
多言語対応には
TextMeshProで多言語対応する場合、英語と日本語だけであれば一つのフォントファイルでほぼすべての文字を扱えるので特になにもしなくてよいのですが
日中台韓など漢字圏の異なる言語に対応しようとした場合は、特別なやり方が必要になってきます。
これには大きく分けて二種類のやり方があります。
1つは、コンポーネントに設定しているフォントアセットそのものを入れ替えるやり方です。Unity公式のLocalizationパッケージなどはこのやり方だと思います。
ですが、全コンポーネントに対応が必要だったり、各言語ごとにフォントアセットだけではなく同じ設定のフォントマテリアルにも対応する必要があったりと手間が多いかもしれません。
もう1つは、フォントは入れ替えずにフォールバックを活用するやり方で、以下ではこちらを説明します。
フォールバックを使った多言語対応
フォールバックを使った多言語対応のイメージは以下の通りです。
基本的となるフォントは英字を収録したフォントアセットになります。
(後から多言語対応する場合は、作成済みのメインとなるフォントアセットを直接アップデートして英字のみのフォントアセットに上書き更新します)
さらに、対応言語ぶんのフォントアセットを別に作ります。(繰り返しになりますが全てのフォントアセットで「Samping PointSize」と「Padding」は統一してくだい)
各言語で使用する文字セットは、なるべくならメインのフォント内に使用されている文字を抜いた文字セットを作成し軽量化しましょう。
また、各言語の文字セットの文字数が多いようなら、上記のフォールバック分割をしておきましょう。

メインとなるフォントを各コンポーネントに設定して開発をしていきます。
メインとなるフォントには、開発者の使用言語のフォントをフォールバックで設定してください。
フォールバックは再帰的に処理されるので、各言語のフォントアセットにさらに分割フォールバックが設定されていても自動的に機能します。

ゲーム実行中は、フォールバックを言語に対応したフォントに入れ替えるプログラムを書いて、ランタイムの起動時や言語変更時に呼び出します。

フォールバックを使うことで、
・テキストオブジェクト単位で設定せずにフォントアセット単位で行えるために数が少なく制御が容易
・フォントマテリアルを言語ごとに用意したりクローンして制御するといった複雑な作業が必要ない。
・各言語フォントをResourecesフォルダ以下に置くなどして動的に必要最小限だけロードするようにすれば最低限のメモリ消費で済む
……といったメリットがあります。
違う言語の漢字圏フォントをフォールバックで混ぜてはいけない
日中台韓のローカライズを考えた場合に、単純に考えるとメインとなるフォントのフォールバックに日中台韓のフォントアセットを全て設定してしまえば良いように思えます。
ですが、これはやってはいけません。
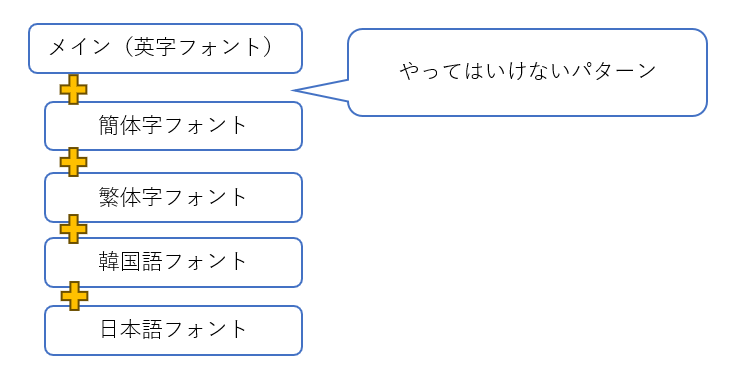
全部のフォントを一度にロードするのでメモリ消費が激増するというのも良くないのですが、
下記のように、日本語で表示しようとしてしてるのに見慣れない漢字が混ざるといったより深刻な問題が生じます。


上記を見比べると、細かいところが違ったり一見して大きく違う誤字のように見える漢字があるのがわかると思います。
これはゲームに限らず多言語対応が不完全なソフトウェアではよく起きている問題で、
「同じUnicodeでも言語によって違う字形(文字の見た目)になる文字がある」ことが原因です。
参考:ゼロから学ぶ「フォントのしくみ」①:言語とスクリプトの関係/繁体字・簡体字・日本の漢字(かんじ)|Fontworks | フォントワークス公式note
TextMeshProでは、フォールバックの設定で繁体字のフォントが日本語のフォントよりも優先度が高く設定されている場合、
日本語の (U+76F4)を表示したいのに、繁体字の
(U+76F4)を表示したいのに、繁体字の (U+76F4)が優先されて表示されしまう……という結果になります。
(U+76F4)が優先されて表示されしまう……という結果になります。
逆に日本語の優先度上げてしまうと、繁体字で表示しようとした場合に日本語のフォントが優先されてしまうため、繁体字圏ではおかしな見た目になってしまいます。
こういった理由で、上記のように言語に対応した適切なフォントを入れ替えて設定する必要があります。
補足:LineMetricsの調整
言語によって元となるフォントファイルが違うため、フォントによってはLineMetricsが違ってしまう場合があり、調整が必要なことがあります。
参考:LineMetricsの落とし穴