TextMeshPro用フォントアセットの作成

投稿日:2023年12月22日 | 最終更新日:2024年5月24日
目次
概要
TextMeshProを使用してテキストを表示する場合、TrueTypeFont(.TTF)などの一般的なフォントファイルではなく、それをもとに作成した専用のフォントアセット(TMP_FontAsset)が必要になります。
ネット上やUnityの使い方を扱った書籍にもやり方は載っていますが、けっこう把握するのが大変なものになっています。
ここでは、「宴」に用意されている補助ツールなどを組み合わせたフォントアセットの作り方をまとめました。
また、宴のサイトではTextMeshProの日本語ドキュメントを用意していますので詳細はそちらも確認してください。
参考:フォントアセットの作成
参考:コラム:TextMeshProで日本語や多言語対応したフォントアセットを作る
フォントファイルを用意
フォントアセットを作るには、元となるフォントファイルが必要です。
「宴」がデフォルトで用意しているフォントではなく他のフォントを使いたい場合は、それを入手してUnityにインポートする必要があります。
また、フォントにはそれぞれ利用ライセンスが定められていますので、それを守るようにしてください。
フォントアセットに収録する文字コレクションを作成する
フォントアセットの作成には、収録する文字がどれなのか指定する必要があります。
この収録文字のリストをここでは「文字コレクション」と呼ぶことにします。
ChatacterCollectionGenerator
プロジェクトWindows内で、右クリック>Create>Utage>Font>ChatacterCollectionGenerator を選択すると、「宴」の文字コレクション作成用のツールアセットを作成することができます。

作成したアセットの名前は、「フォント名 Collection」や「プロジェクト名 Character Collection」のようにわかりやすい物に変えてください。
フォントファイルに収録されている全ての文字を出力する
フォントファイル内にある全ての文字を出力するには、以下のように設定します。
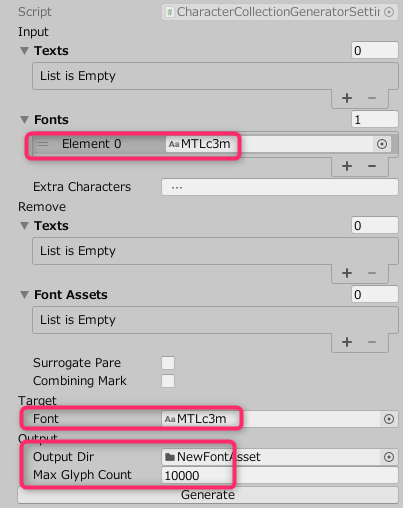
Inputの「Fonts」とTagetの「Font」にフォントファイルを設定し
「Out Put Dir」に出力先のディレクトリを設定
「Max Glyph Count」は、10000を設定してください。
フォントファイル内の文字を全て使うのは多すぎると思う人もいるかもしれません。
日本語の場合、文字コレクションには色々な規格があって、第一水準や第二水準といった規格や、それと似たようなAdobeの定めた規格などもよく使われていますので、それらを使用するのが一般的かもしません。
ですが、ここでは次のような理由であえてすべての文字を収録するようにしています。
・ノベルゲームの場合は一般的なゲームよりも扱う文字が豊富であることが望ましい
・フォントファイルに収録されている文字は、一般的な規格の文字コレクションに従っていることが多いので、わざわざ他の規格を使っても大差がないことが多い
・一般的な文字コレクションの規格にあってフォントファイル内にない文字は、どのみちフォントアセットに組み込めないのであまり意味がない
・収録文字を制限すると、文字化けする可能性が高まり、エラーチェックをしたり文字化け解消のためにフォントアセットを作りなおす手間が増える可能性が高くなる
文字コレクションの出力
「Genrerate」ボタンで文字コレクションが出力されます。
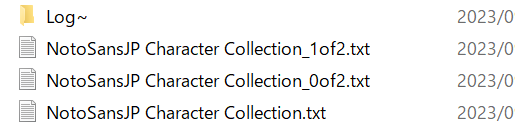
「ChatacterCollectionGenerator」と同名の.txtファイルにはすべての文字コレクションが収録されています。
フォントファイル内の収録文字数が多く、「Max Glyph Count」で指定した数よりも多いグリフが収録されている場合は、
_0_of2.txt、_1_of2.txtのように、収録されるグリフ数が「Max Glyph Count」以下になるように分割したテキストファイルが同時に生成されます。
ログは「Log~」というサブフォルダがさらに作られその中に出力されます。
~が末尾につくフォルダはUnity上では確認できなくなるので、必要に応じてエクスプローラー上などで確認してください。
ChatacterCollectionGeneratorリファレンス
ChatacterCollectionGeneratorはローカライズなどのフォールバックフォントのための文字コレクションを作成するためにも使用できます。
フォントファイルの全ての文字を収録するのではなく、なんらかの制限を加えたいときなどは、以下のリファレンスを参考に設定をしてください。
| カテゴリ名 | 名前 | 内容 |
|---|---|---|
| Input | 収録する文字の情報。 ここに設定された文字情報のうち、TargetのFontに設定されたフォントファイル内にある文字が出力される。 |
|
| Texts | 収録文字候補のテキストファイル。 テキストファイル内にある文字が収録文字候補となる。 第一水準など一般的な規格の文字コレクションのテキストを設定すれば、その規格の範囲内に出力文字数を制限できる。 |
|
| Fonts | 収録文字候補のフォントファイル。 TargetのFontと同一のフォントファイルを設定すると、フォントファイル内のすべての文字が出力対象となる |
|
| Extra Characters | 必ず収録する文字 TextMeshProの仕様上必要な予約文字'_'(アンダーバー)と'…'(リーダー)がデフォルトで設定されている。 Removeで設定された情報よりも優先される。 |
|
| Remove | Inputから除外する文字の情報 「フォールバックにある他のフォントアセットが使用している文字は除外したい」といった目的で使用する |
|
| Texts | 除外する文字のテキストファイル | |
| Fonts | 除外する文字のフォントファイル | |
| Surroaget Pare | サロゲートペア文字を除外したい場合にオンにする | |
| Combining Mark | 組み文字を除外したい場合にオンにする | |
| Target | ||
| Font | 文字コレクションの作成対象となるフォントファイル。 | |
| OutPut | ||
| OutPutDir | 文字コレクションとログの出力ディレクトリ | |
| Max Glyph Count | 1つの文字コレクションファイルが扱うことになる最大グリフ数 扱う文字数が多すぎると、テクスチャに焼きこむ際に1つの画像に収められなくなってしまう。 そのため、最大数を指定することで、文字コレクションを複数に分割して複数のフォントアセットに分割しやすくしている。 |
|
| Generate | 文字コレクションファイルの生成ボタン |
フォントアセットの作成
Font Asset Creator
TextMeshProのフォントアセットを作成するには、Window>TextMeshPro>Font Asset CreatorからTextMeshPro公式のフォントアセット作成ツールを開きます。
推奨設定
各種の項目の推奨設定は以下の通りです。
基本的には「宴」のデフォルトのフォントアセットの設定と同じです。
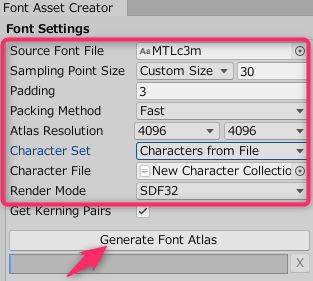
「Source Font File」に、対象のフォントファイルを設定してください。
「Sampling Point Size」は「Custom Size」「30」
「Padding」は「3」
「Paking Method」は「Fast」(収録文字がギリギリ漏れる場合はOptimumに変更)
「Atlas Resolution」は「4096」「4096」
「Character Set」は「Characters from File」
「Character File」に、ChatacterCollectionGeneratorで作成した文字コレクションファイルを設定してください。
_0_of2.txt、_1_of2.txtのように複数に分割されている場合は、最初は0番のファイルを設定してください。
「Render Mode」は「SDF32」
「Get Kerning Pairs」はオンのままで。
作成
「Generate Font Atlas」をクリックするとフォントアセットの作成が開始されます。
これには数分~数十分と長時間かかります。
また、一度に扱う文字数が多い場合は、作成中にかなりPCのメモリを使います。ハイスペックなPCではない場合は、なるべく他のアプリケーションを終了させるなどして、メモリに余裕を持たせておきましょう。
作成が終わったら、「Save」ボタンでフォントアセットとしてファイル保存します。
この時、新規保存する際のファイル名はデフォルトでは「フォント名 SDF」となっているのですが、
「プロジェクト名+フォント名+番号」のように、明確に区別がつくものしたほうが良いです。
例)「ProjectNameNotoSans0 SDF」や「ProjectNameNotoSansMain SDF」
参考:フォントアセットの名前は「フォント名 SDF」のままでつけない
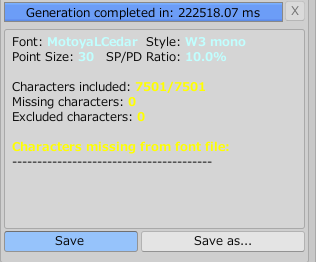
収録文字数が10000万を超えて、_0_of2.txt、_1_of2.txtのように複数に分割されている場合は、0番に続いて、1番、2番と文字コレクションファイルだけ変えて、同じ設定でフォントアセットを複数作成してください。
調整
上記の手順は、なるべく多くのパターンに対応できるような汎用的な設定です。
値を調整することで、最適化することも可能です。
たとえば、文字コレクションが複数に分割されていている場合でも、生成されたAtlas画像に余白が多いようであれば、ChatacterCollectionGeneratorの「Max Glyph Count」を増やすなどして、一つのフォントアトラスにたくさんの文字を収録して分割数を減らしたりすることも可能です。
フォールバックの設定
フォントアセットを複数に分割している場合は、フォールバックを設定して複数のフォントをつなげる必要があります。
0番のフォントアセットのインスペクターの「Fallbak Font Assets」の「Facllback List」に1番以降のフォントアセットを設定してください。

フォールバックは「このフォントアセットで表示できる文字が見つからなかったら、フォールバックに登録されているフォントアセットの文字データを探してそれを表示する」という機能です。
つまり、0番に1番以降のフォントアセットを登録しておけば、0番のフォントを描画に使えばよくなります。
Material Presetの作成
TextMeshProのMaterial Presetは、テキスト表示にアウトラインやシャドウ、グローなどの効果をつけるためのものです。
LegacyTextでは、各テキストオブジェクトのコンポーネントでそれらを設定できましたが、TextMeshProではマテリアルを作っておいて、それを設定する形になります。
宴の場合は、メッセージウィンドウのテキスト表示のデフォルトではアウトラインがつくようなマテリアルを設定していますので、それの作成手順を例にして説明します。
まず、任意のシーン内にText表示オブジェクトを作成し、使用したいフォントを設定します。
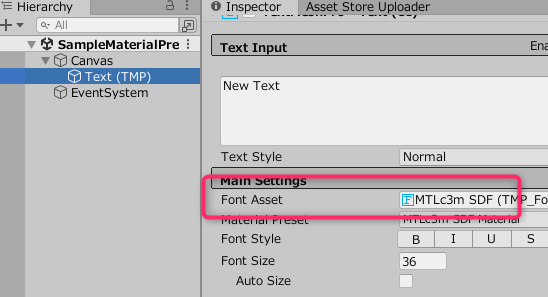
次に、最下段のマテリアル表示項目の右上の設定から「Create Material Preset」を選択します。
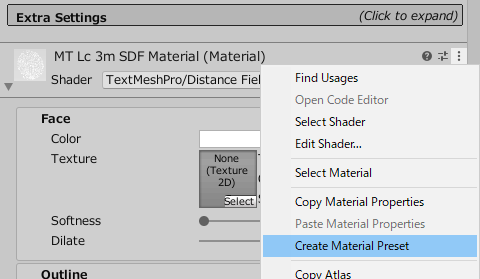
Projectウィンドウ内にマテリアルが作成されます。
名前の末尾に「Outline」などの用途にあったものをつけておきましょう。

次に、マテリアルの各種のパラメーターを編集して目的にあった効果をつけます。
アウトラインをつけるなら次のような設定をするのが簡単です。
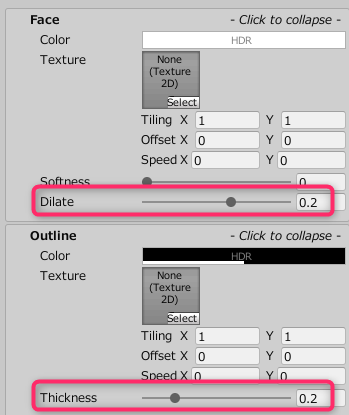
各項目の値の意味など、詳細な説明はこちらをご確認ください。
TextMeshProのマテリアル
「Line Metrics」の調整
基本的にはフォントアセットは、作成後特にいじる必要はないのですが、
「上寄せ表示したときに、逆に下側で表示されてしまう」または「中央表示してるつもりが、微妙に上または下にずれている」といったように、表示位置がずれてしまうことがあります。
フォントファイルによってこれが起きたり起きなかったりします。表示がおかしいと思った場合は、詳しくは「Line Metrics」の落とし穴 を確認してください。
調整が必要な場合は、下記の手順で調整してください。
TextMetricsAdjuster
Line Metricsの調整補助ツールです。(宴4.0.3以降で使用可能)
AscentLineと、DescentLineを手動調整しても、フォントアセットが更新するたびにもとに戻ってしまったりするため、
設置値を生成、保存可能にして各フォントに自動設定可能なようにした補助ツールです。
プロジェクトWindows内で、右クリック>Create>Utage>Font>TextMetricsAdjuster を選択することで作成可能です。
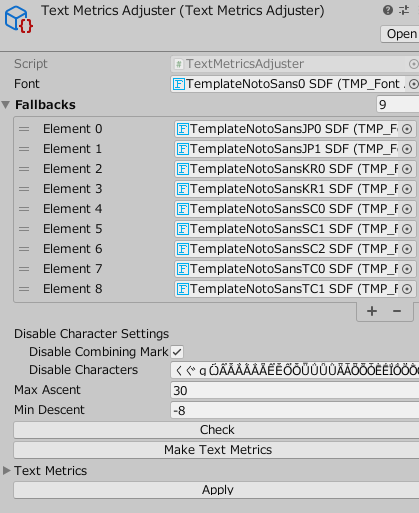
| 名前 | 内容 |
|---|---|
| Font | 調整対象のフォントアセット |
| Fallbacks | 対象フォントにフォールバックとして設定するフォント。 ローカライズでフォールバックを切り替える場合は、全てのフォントアセットを設定すること。 |
| Disable CombingMark | ONの場合、発音記号などの組み文字を調整処理から除外する。 |
| Disable Characters | 調整処理から除外する文字。 デフォルトでは「〱〲」という、日本語の縦読みで使う記号文字が設定されている。 |
| Max Ascenet | 設定したいAscenet Lineの最大値 |
| Min Descent | 設定したいDescent Lineの最小値 |
| Check | 除外設定以外の文字がMin Descent~Max Ascenetの範囲内に収まっているかチェック |
| Make Text Metrix | 文字が収まる範囲でMetrixの値を作成 一度作成した設定を変えたくない場合は、これを使わずにCheckやApplyのみをすること |
| Apply | 作成済みのMetrix値をすべてのフォントに適用 |
TextMetricsAdjusterの使い方
-
FontとFallbacksを設定する
-
Max Ascentに、設定したいAscent Lineの値を設定。(よくわからない場合は、「PointSize」の値をそのまま入力)
-
Min Ascentに、設定したいDescentLineの値を設定。(よくわからない場合は、「CapLine - PointSize」の値を入力)
-
「Check」ボタンをクリック。
Min Descent~Max Ascenetの範囲からはみ出る文字が合った場合、
各フォントごとにコンソールログにエラーが出力される
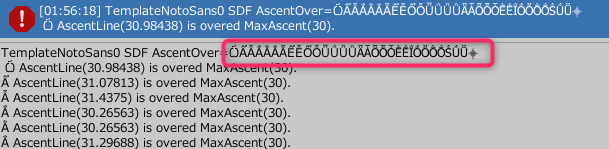
1行目に、はみ出た文字一覧が出力され、
2行目以降に、はみ出た文字ごとに、はみ出た位置が表示される。
AscentLine(31.07813) is overed MaxAscent(30).なら、設定値は30までだけど、31.087813まではみ出ているという意味。 -
滅多に表示しない文字や記号的な文字でAscent LineやDescent Lineの範囲外で構わない文字は「Disable Characters」に追加
-
はみ出た文字に合わせてAscent LineやDescent Lineを広げる場合は、Max AscenetやMin Descentを調整しなおす。
-
4~6を繰り返して、値を調整してエラーが出ないようにする。
-
Warningがでていないかチェックする。

最終的に作成するAscentLineとDescent Lineは、その中間がCapLineの中間と一致するように調整される。
その結果、Min Descent~Max Ascenetの範囲からはみ出すような場合、Warningを出力する。
特に問題ないと思うなら無視しても良いし、Max AscenetやMin Descentを調整しなおしても良い。 -
「Make Text Metrix」ボタンでMetrixが作成されます。結果は「Text Metrix」以下に上書きされます。
-
「Apply」ボタンで生成したMetrixの値を各フォントのFaceInfo以下に上書き設定します。
ローカライズする場合
TextMeshProではあらかじめ用意したフォントの文字しか表示できません。(将来的には改善予定らしいです)
そのため、ローカライズする場合は、あらかじめその国の文字を表示可能なフォントを用意しておく必要があります。
英語と日本語であれば、おそらく日本語フォントに収録されているアルファベットのみで可能なので特に何もする必要はないです。
ただ、標準的なアルファベット以外の文字は収録されているとは限らないため、その文字を扱っているフォントファイルを探してフォントアセット作成し、フォールバックに追加する必要があります。
さらに厄介なことに、繁体字、簡体字、韓国語などでは、日本語で使う同じ漢字の文字コードであっても、フォントのグリフデータ(見た目)が違うことがあるため、言語によってフォントアセットそのものや、登録されたフォールバックを切り替えるといったことが必要になります。
参考:TextMeshProのフォントをローカライズする